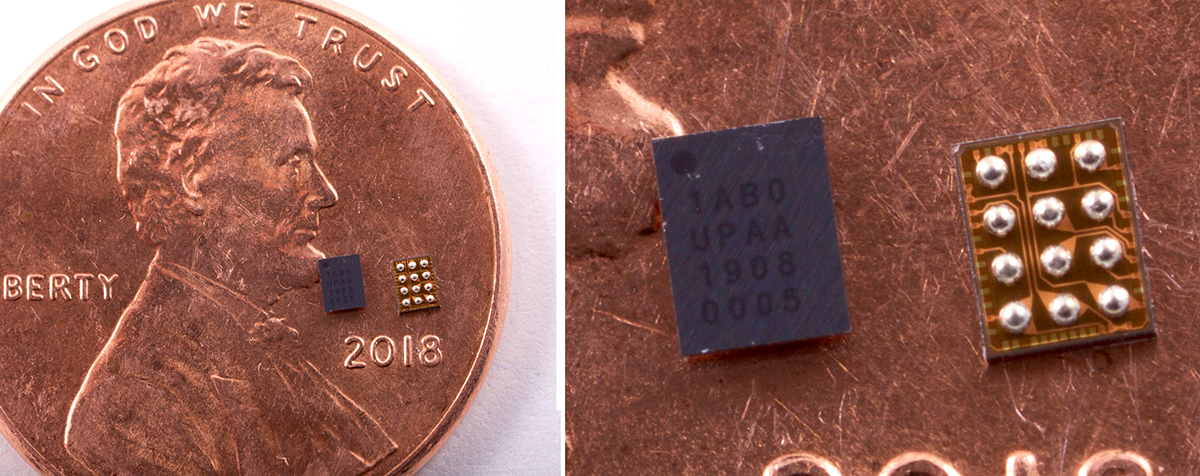In a guest editorial back in 2017, I remarked that most of us spend much of our time staring at our smartphone but hearables may change that focus to listening to a voice in our head. Well, with all the stresses we are facing these days perhaps more of us are hearing a different kind of voice in our heads. But hearables have yet to dominate our mindshare.
"Hearable" is a hybrid of the words - wearable and earphone, combining major aspects of wearable technology with audio-based information services, music, and wireless communications. As with smartphones and smartwatches, the hearable aspires to be a computing platform running applications, through intelligent virtual assistants, and conferring private guidance to the wearer. The more ambitious designs support local audio playback and recording, making it a digital audio player and Dictaphone in your ear.
The concept of the autonomous multi-function hearable will challenge the smartphone just as the iPhone extinguished the existence of both the iPod and the Blackberry personal digital assistant. The user interface for the most sophisticated hearables will migrate away from the user having to poke at the device's buttons on their ear or whack their ear, instead shifting toward intuitive voice commands empowered with artificial intelligence to interpret what is being asked of it.
|
|
|
Syntiant's Neural Decision Processors (NDPs) are now in more than one million devices!
|
At the product development level, there are considerable but surmountable challenges of hearables - such as the dense mechanical packaging, ambitious signal processing, stable RF reception, and battery life (or lack of it). After extensive development both by persistent startups, established brands and factory engineering teams, stable high performance and longer battery life is just becoming attainable. All the pieces exist, yet all these pieces of the puzzle have yet to coalesce.
Cloud computing and artificial intelligence (AI) have been the driving forces in the adoption of speech recognition in virtual assistants, but there has been an inherent limitation due to its reliance on connectivity. Pivotal is voice command without the latency and power consumption of cloud connectivity, instead relying on processing on-board the device rather than heading out to the cloud and back. The buzzword for this is Edge AI, and this approach can complement the cloud or even eliminate it while facilitating context-aware and power-efficient voice interfaces that are cost-effective.
For me, this is déjà vu. Back 50 years ago when I was at New York University (NYU), I took a computer course at the Courant Institute of Mathematical Sciences, the university computer center. We had a CDC 6600 mainframe, which was shared with the Deptartment of Defense. An armed squad protected this national asset of a central computer strung out to many dumb terminals. As technology moves forward, stuff gets smarter and smaller and "big daddy" is progressively going away toward stand-alone distributed processing. My new Lenovo laptop with core i7 shames that CDC supercomputer the same way as hearables will soon shame my laptop.
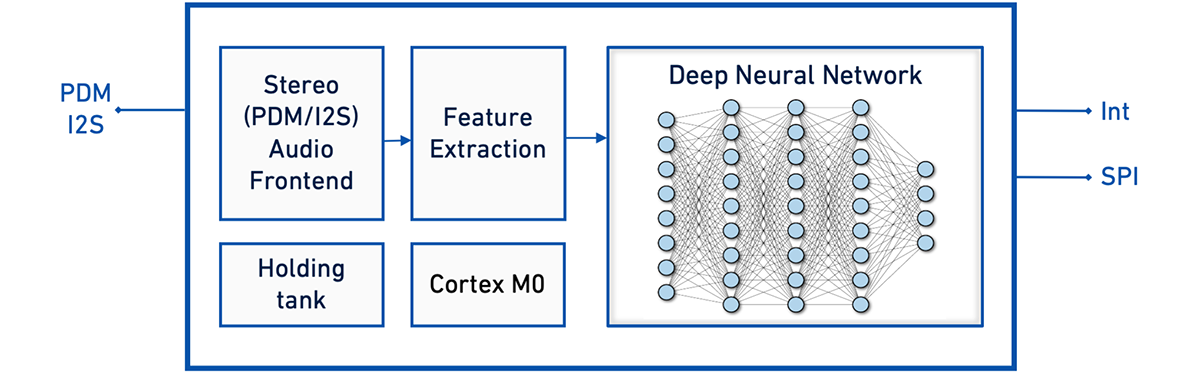
Moving edge AI voice and sensor solutions forward is California-based Syntiant, which has commercialized the concept with its NDP100 and NDP101 Neural Decision Processors (NDPs). Proven use cases include wake words, command words and sentences, speaker identification, and event detection - all onboard the chip.
The Syntiant NDPs have been designed into a wide range of battery-powered edge devices, such as phones, smart speakers, laptops, hearing aids, and earbuds with more than 1 million units shipped. That's because Syntiant's processors offer approximately 200x the power efficiency (less than 140 microwatts for always-on-voice), and 20x the throughput, compared to current MCU and DSP solutions.
|
|
|
Currently in production with Amazon's Alexa Voice Service firmware, the NDP10x family makes Always-On Voice interfaces a reality and support entirely new form factors.
|
I've been researching the topic and particularly the implementation in true wireless stereo (TWS) earbuds. In talking with Syntiant's Ted Kao, Director, Product Management, he has provided a "cheat sheet" on "Edge AI".
Shifting voice recognition from the cloud to the edge can offer the following benefits:
- With increasing user privacy concerns and regulations, performing speech recognition using a cloud-based provider may not always be viable. Uploading personal voice recordings is especially risky in data-sensitive applications such as healthcare and finance.
- In voice user interfaces (VUIs), milliseconds of delay matter. Responsiveness is crucial in TV, AR, and VR applications, where voice could be used as the primary method of interaction.
- Cloud voice processing necessitates continuous Internet connectivity. Even straightforward voice interactions (e.g., asking Siri for the time of the day) requires an Internet connection. In many applications, such as automotive, fickle Internet access can disrupt the user experience.
- On battery-powered devices, Internet access is a major power drain due to radio activity (especially on LTE and Wi-Fi).
- Cloud computing is not cost-effective in the long term. Google DialogFlow and Amazon Lex charge per API call, and cost can be prohibitive. Edge processing taps into on-device compute resources to reduce or eliminate cloud and connectivity expenses.
- NDP custom silicon is optimized to handle various workloads in deep learning, and it utilizes neural network to crunch data and identify patterns.
Neural Decision Processors (NDPs) - Drilling Deeper
In AI, fast access to data and computational capability and power are significant challenges. Traditional CPUs and DSPs are stored memory architectures and lack inherent capabilities for massive parallel processing required by deep neural networks. When millions of multiplies and accumulates can be done in parallel in memory or near memory we can effectively linearly scale AI.
Voice is quickly becoming a de facto standard user interface but the majority of voice driven devices today (e.g., smart speakers, smart displays, TVs, security cameras, etc.) still have to run on AC power. With NDP, having a robust voice interface becomes possible even for battery-powered devices s(e.g., wearables and hearables such as TWS). For TWS earbuds that cannot include large batteries due to its form factor, Syntiant's NDP would be an ideal solution to keep the Bluetooth SoC in deep sleep, while allowing the device to detect wake word or voice commands and take appropriate actions when needed.
For battery operation, low power silicon as well as high-performance voice interfaces are equally important. In traditional low power DSPs, creating a small model that can achieve low false acceptance (FA) has been a challenge. Without low FA, the system and the main processor would be woken up often, which would reduce battery life. With the neural network packed into NDP, the FA is minimized to keep the system asleep and as a result keep the energy consumption low. In the case of remote controls with 2x AA batteries, traditional DSPs with wake-on-voice would last 4 to 6 months if the device is always listening. However, battery life would be significantly reduced if the remote often gets woken up due to false alarms, and these are problems NDPs address with their low-energy, high-performance capabilities.
|
|
|
Syntiant offers complete software development and evaluation tools. The NDP9101B0 Development platform is implemented as a Raspberry Pi shield with easily configurable jumpers to connect a number of different microphones and sensors.
|
In terms of robustness of voice solutions, Syntiant has established it's own data management and pipeline modeling team to continuously collect voice data and create production quality models. With a good amount of data and robust neural network training pipeline, false rejection (FR) performance that could be affected by how different people talk or the different accents, can be significantly improved.
Aside from providing voice interface solutions, NDPs with microphone inputs can also be used to detect acoustic events (e.g., glass breaking, a baby crying, fire alarms) or performing scene analysis to understand whether the device is in a café, on a train or an airplane, and so forth. Speaker identification and verification are also use cases that can be supported to identify who is speaking or allowing the device to only take commands from specific person.
Syntiant is introducing their second-generation processors in early 2021, packing more neural network capability while maintaining ultra-low power supporting not only voice but also sensor fusion.